TurboQuant:一篇论文砸崩存储股价?MNN在手机上跑通了
一、问题背景
最近几天,Google 的一篇量化论文 TurboQuant(2025 年 4 月挂 arXiv,已被 ICLR 2026 接收)突然在社区火了。没有财报暴雷、没有供应链断裂,但美光和西部数据两家存储芯片巨头的股价应声大跌——一句”不需要那么多显存”的暗示足以让市场敏感(当然也有人猜测是被人拿来做空存储的由头)。很快就有人在 GitHub 上给 MNN 提了 issue #4321,希望我们能支持这个量化方法。MNN 一直聚焦端侧推理,手机内存寸土寸金,我们自己也急需优化 KV Cache 的内存占用。于是我抓紧读了论文,结合端侧的计算特点做了适配和优化实现。
为什么这篇论文引起这么大关注?因为它切中了大模型推理的核心痛点——KV Cache 的内存占用。
大语言模型推理时,每生成一个 token 都要和之前所有 token 的 Key/Value 向量做 Attention 计算。这些向量被缓存在 KV Cache 中,内存占用随上下文长度线性增长——Qwen3-4B 跑 8K 上下文,光 KV Cache 就要吃掉约 2GB。如果能把 fp16 的 KV Cache 压缩到 3~4 bit,内存立省 30%~60%。
问题在于:怎么压得更小,又不把模型压坏?
TurboQuant 给出了一个数学上优雅、工程上简洁的方案:先用正交旋转把向量的统计分布变成”已知形状”,再用针对该分布预先算好的最优码本进行量化。不需要训练数据、不需要校准集、码本直接硬编码——整个量化过程纯在线计算,零数据依赖。
本文从算法原理、MNN 工程实现、端侧实验三个维度,完整拆解这一方案。
二、论文解析
2.1 一张图看懂完整流程
下图展示了 TurboQuant 对一个 32 维 block 的完整量化过程:
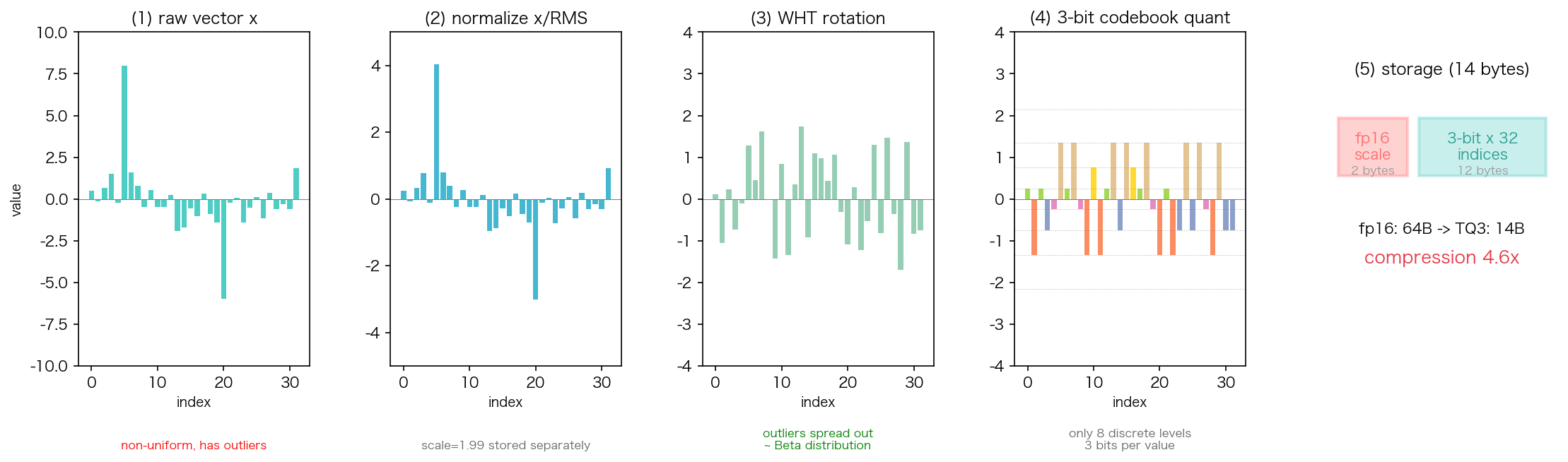
整个过程可以用三行伪代码概括:
输入:d 维向量 x(一个 Key 或 Value 向量)
Step 1. norm = ||x||₂;x_hat = x / norm ← 归一化到单位球面,单独存 norm
Step 2. y = Π · x_hat ← 用正交矩阵旋转
Step 3. indices[i] = codebook_search(y[i]) ← 逐坐标标量量化
反量化就是反过来:查码本 → 逆旋转 → 乘回 norm。
每一步都有清晰的目的:
| 步骤 | 操作 | 目的 |
|---|---|---|
| ① | L2 归一化 | 分离”大小”和”方向”——方向用码本量化,大小(L2 范数)用 fp16 精确存储 |
| ② | 正交旋转 | 让每个坐标的分布变成已知且固定的 Beta 分布 |
| ③ | 码本量化 | 利用已知分布,用预计算的 Lloyd-Max 最优码本逐坐标量化 |
关键洞察:步骤②是核心。 旋转不仅”打散离群值”(QuaRot 也这么做),更关键的是让旋转后每个坐标的统计分布变成精确已知的形状——这使得我们可以预先计算信息论意义上的最优量化码本,而不是使用次优的均匀量化。
2.2 为什么旋转能让分布变已知
这是整个算法最关键的洞察。
地球仪类比:你在地球仪上标了一个点(原始向量归一化后的方向),然后随机转动地球仪(乘正交矩阵)。不管你一开始标在哪里,转完之后这个点在球面上的位置是完全随机的——等价于在球面上均匀选一个点。
数学上说:归一化后的向量在单位球面上,乘以随机正交矩阵相当于在球面上做均匀随机旋转。旋转后,每个坐标的分布由纯几何决定:
第 j 个坐标 y_j 的概率密度:f(t) ∝ (1 - t²)^((d-3)/2), t ∈ [-1, 1]
这就是 Beta 分布,形状只取决于维度 d,跟输入向量完全无关。
直觉理解:在 d 维单位球面上,满足”第 j 个坐标 = t”的点构成一个 (d-2) 维的低维球面,其半径为 √(1-t²),”面积”正比于 (1-t²)^((d-2)/2)。t 越接近 0,低维球面越大,落在这个区间的概率越高;t 接近 ±1 时,低维球面缩成一个点,概率趋向于零。这就是 Beta 分布的几何来源。
下图展示了不同维度下 Beta 分布的形状,以及在此分布上设计的 Lloyd-Max 最优码本:
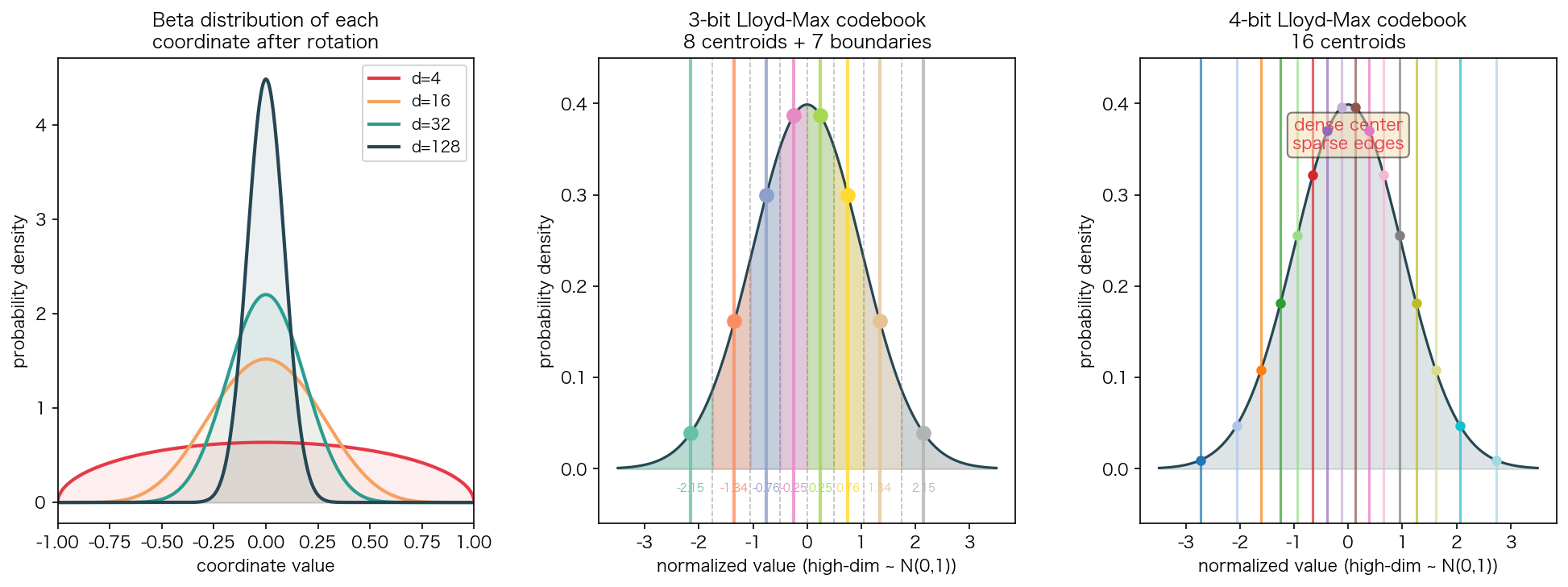
高维效应:维度越高,分布越集中在 0 附近。当 d=128(典型的 head_dim)时,每个坐标的标准差仅 ≈ 1/√128 ≈ 0.088,Beta 分布几乎退化为高斯分布 N(0, 1/d)。
关键推论:
- 维度 d 确定 → Beta 分布确定 → 最优码本确定 → 预计算一次,永久使用
- 高维球面上各坐标近似独立,因此 d 维向量量化问题可以拆成 d 个独立的一维标量量化——VQ 退化为 SQ,实现极其简单
2.3 Lloyd-Max 最优码本:一维 k-means
既然知道了每个坐标的精确分布,就可以用经典的 Lloyd-Max 算法 计算信息论意义上的最优码本。
Lloyd-Max 本质上是一维连续 k-means:
- 把值域分成 2^b 个区间(b 是 bit 数)
- 每个区间的”代表值”(centroid)是该区间内的概率加权中心
- 区间边界是相邻代表值的中点
- 迭代直到收敛
从上面的码本图可以看到一个重要特征:中心密集,边缘稀疏。这正是 Lloyd-Max 相对于均匀量化的优势——把更多的码本资源分配给概率密度高的区域。
因为分布的公式已知,可以用数值积分精确计算,不需要训练数据、不需要校准集。码本可以直接硬编码:
| bit 数 | 码本大小 | 代表值(对称) |
|---|---|---|
| 3-bit | 8 个 | ±0.245, ±0.756, ±1.344, ±2.152 |
| 4-bit | 16 个 | ±0.128, ±0.388, ±0.657, ±0.942, ±1.256, ±1.618, ±2.069, ±2.733 |
论文证明了 MSE 的理论上界:MSE ≤ 2.7 / 4^b,信息论下界是 1/4^b,仅差 2.7 倍常数——接近理论最优。
2.4 有偏内积与 QJL 修正
在 Attention 中,我们真正关心的不是向量重建误差(MSE),而是 Q·K 内积的准确性。MSE 最优的量化器在估计内积时是有偏的——内积会被系统性地缩小:
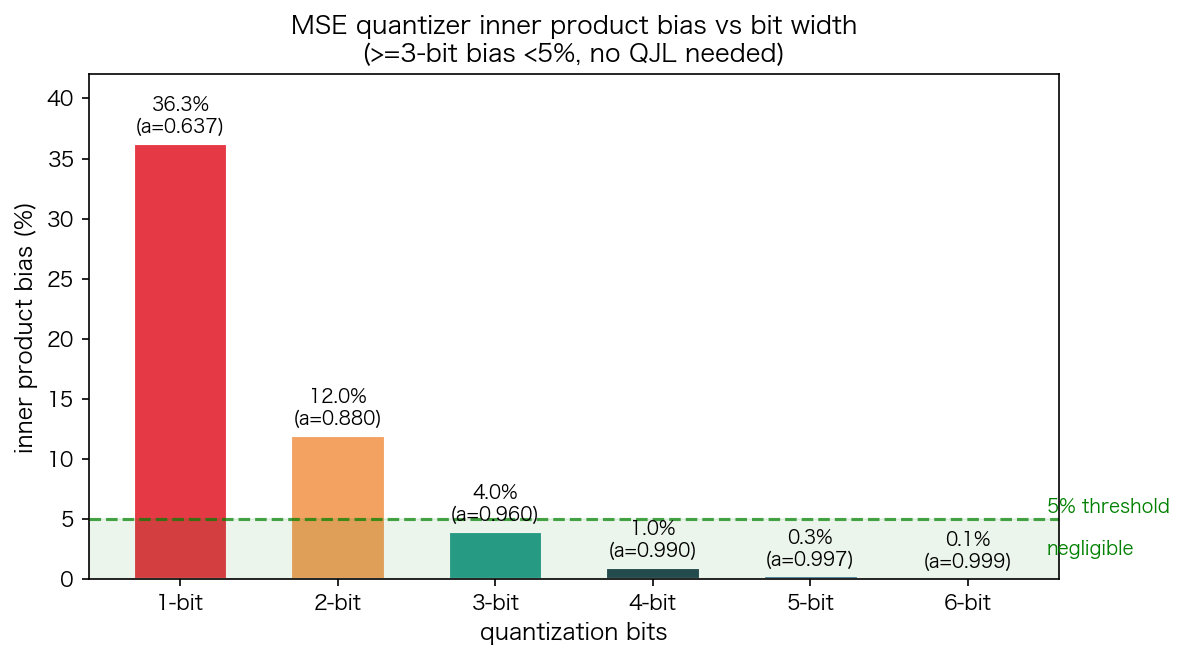
可以看到,3-bit 时偏差仅 4%,4-bit 时几乎无偏(1%)。对于实际使用的 3~4 bit 量化,这个偏差足够小,不需要额外修正。
对于极低 bit(1~2 bit),论文提出了两阶段方法:用 (b-1) bit 做 MSE 量化,剩余 1 bit 用 QJL(Quantized Johnson-Lindenstrauss)做无偏内积修正。QJL 是一种基于随机投影取符号的 1-bit 方案——不追求重建精度,但保证内积估计的期望无偏。
工程启示:3-bit 和 4-bit 场景下,偏差足够小,不需要 QJL 第二阶段。MNN 的实现正是采用了这一策略——全部 bit 预算给 MSE,省掉 QJL 的存储和计算开销。
三、MNN 工程实现
MNN 的实现代码在这个 commit 中,包含 TQ3(3-bit)和 TQ4(4-bit)两种 KV Cache 量化模式,核心代码在 TurboQuant.hpp(约 780 行)。
这个实现是在 Claude 的协助下完成的。一开始我问 Claude 这个方案对 MNN 是否有价值,它直接从论文判断——认为随机正交矩阵和 QJL 会显著拖慢推理速度,在端侧不太划算。在我的建议下,我们做了两个关键调整:用 Hadamard 变换替代随机矩阵,以及只实现 3/4-bit 从而完全避开 QJL。最终实测性能影响很小,decode 速度甚至还有提升。
下面分析几个关键的工程决策。
3.1 用 Hadamard 替代随机正交矩阵
论文用随机正交矩阵 Π 进行旋转,需要 O(d²) 存储和 O(d²) 乘加运算,工程上成本太高。
MNN 借鉴 QuaRot 的思路,采用 Walsh-Hadamard 变换(WHT) 替代。为什么 Hadamard 矩阵可以替代随机正交矩阵?因为 Hadamard 矩阵本身就是只有 ±1 元素的正交方阵(归一化后行列两两正交),满足 TurboQuant 所需的正交性条件。配合符号翻转(用黄金比例哈希生成的确定性 ±1 序列逐坐标翻转),可以引入足够的伪随机性来打散输入结构。
这一替代对端侧计算极其友好:
| 对比项 | 随机正交矩阵 | Hadamard + 符号翻转 |
|---|---|---|
| 存储 | d×d 浮点数 | 零存储(原地计算) |
| 计算 | O(d²) 乘加 | O(d log d) 纯加减法 |
| 元素值 | 任意浮点数 | 只有 ±1(乘法变加减法) |
| 实现 | 矩阵乘法 | 蝶形运算(类似 FFT) |
WHT 的蝶形运算结构如下图所示(以 8 点为例,实际实现为 32 点 = 5 级):
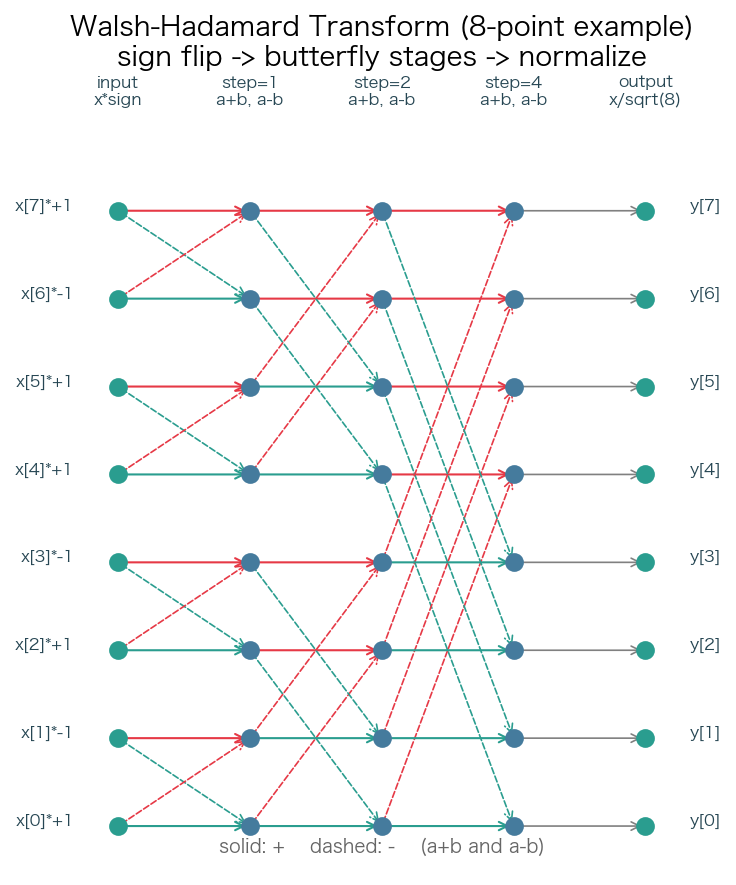
block_size = 32 的选择:不对整个 head_dim(如 128)做 WHT,而是分成 32 维的小块独立处理。每个 block 有自己的 norm(L2 范数),能部分补偿小块维度不够高带来的近似误差。32 维的 WHT 只需 5 级蝶形(log₂32 = 5),计算极快且内存友好。
3.2 只做第一阶段(MSE 量化)
论文的完整方案是两阶段(MSE + QJL),但 MNN 只实现了第一阶段:
论文: (b-1)-bit MSE + 1-bit QJL = b-bit 无偏
MNN: b-bit MSE = b-bit 有偏但精度更高
理由:3-bit 偏差仅 4%、4-bit 仅 1%,实际可忽略;省掉 QJL 的随机投影矩阵存储和额外计算;同样 b-bit 预算全部给 MSE,重建精度更高。
3.3 内存布局与 Attention 融合优化
紧凑的 bit 压缩存储
每个 32 维 block 的存储格式:
| 方案 | 格式 | 总字节 | 等效 bits/value |
|---|---|---|---|
| TQ3 | [2B fp16 norm] + [12B packed 3-bit×32] | 14 字节 | 3.5 |
| TQ4 | [2B fp16 norm] + [16B packed 4-bit×32] | 18 字节 | 4.5 |
| fp16 | [64B fp16×32] | 64 字节 | 16 |
3-bit 索引的 pack 方式是把 8 个 3-bit 值塞进 3 个字节(24 bit),通过位移和掩码操作实现紧凑存储。4-bit 则直接两个索引共用一个字节。
压缩比:TQ3 ≈ 4.6x,TQ4 ≈ 3.6x。
Key 路径:旋转域点积(跳过逆 WHT)
计算 Q·K 时,利用正交矩阵的性质 ⟨Q, Π^T·y⟩ = ⟨Π·Q, y⟩,将 Q 预先旋转到 WHT 域,然后直接和量化后的 K 在旋转域做点积。K 不需要逆 WHT 变换——每个 KV token 只需 unpack 索引、查码本、做乘加。Q 的 WHT 变换在每个 head 计算开始时做一次,对该 head 所有 KV token 复用。
Value 路径:旋转域累加(N 次逆 WHT → 1 次)
计算 Softmax(QK)·V 时,先在旋转域累加所有 V 的加权和(每个 V 只需查码本乘以 attention weight),最后只做一次逆 WHT 变换。从 N 次逆 WHT(N = KV 序列长度,可达数千)减少到 1 次,性能收益显著。
量化写入路径
KV Cache 在每次 Attention 写入时就地量化——从 fp16/fp32 源读取 32 个值到 float buffer,计算 L2 范数并归一化,执行 WHT 正变换,码本搜索得到索引,pack 为紧凑格式写入 cache。不需要额外的 fp16 缓冲区。
3.4 NEON SIMD 加速
在 aarch64 平台上,MNN 对三个热点路径做了 NEON 向量化优化:
- 码本查找:利用
vqtbl1q_u8(向量表查找指令)一次性将 8 个 3-bit 索引转换为 8 个 fp16 码本值,避免逐个标量查表 - 3-bit 解包:利用
vshlq_u32(变量移位)配合掩码,一条 SIMD 指令提取 4 个 3-bit 索引 - 码本搜索:利用
vcgtq_f32(向量比较)做 7 次边界比较,通过累加比较结果得到索引,4 个值并行处理
实测 NEON 优化对 prefill 提升有限(+1~5%),因为 prefill 瓶颈在上游的 GEMM 计算而非量化本身。
四、实验结果与分析
在 macOS ARM64(Apple Silicon)上测试了两个模型:Qwen3-4B(2.34 GiB)和 Qwen3-0.6B(355 MiB),使用 FlashAttention + ChunkPrefill(chunk=256),4 线程。
4.1 精度:PPL(Perplexity)
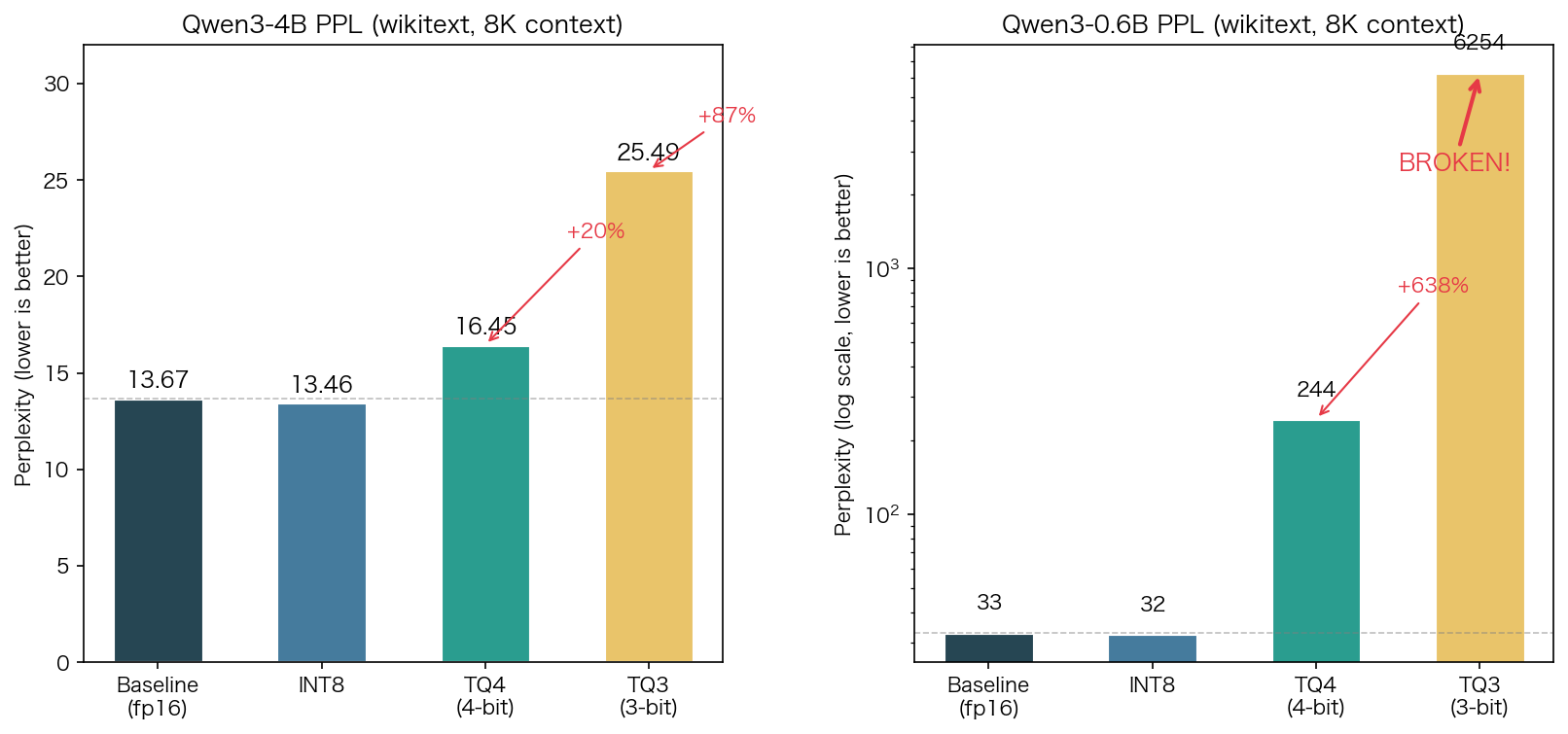
| 模型 | Baseline (fp16) | INT8 | TQ4 (4-bit) | TQ3 (3-bit) |
|---|---|---|---|---|
| Qwen3-4B | 13.67 | 13.46 (-1.5%) | 16.45 (+20%) | 25.49 (+87%) |
| Qwen3-0.6B | 33.02 | 32.49 (-1.6%) | 243.81 (+638%) | 6253.83 (崩坏) |
- 4B 模型上 TQ4 PPL 增长 20%,考虑到从 16bit 压缩到 4.5bit(压缩 3.6x),这是合理的精度-压缩权衡
- 4B 模型上 TQ3 PPL 增长 87%,压缩更极致(4.6x)但精度损失显著增大
- 0.6B 模型上 TQ3/TQ4 均严重崩坏——原因见后面分析
4.2 速度与内存
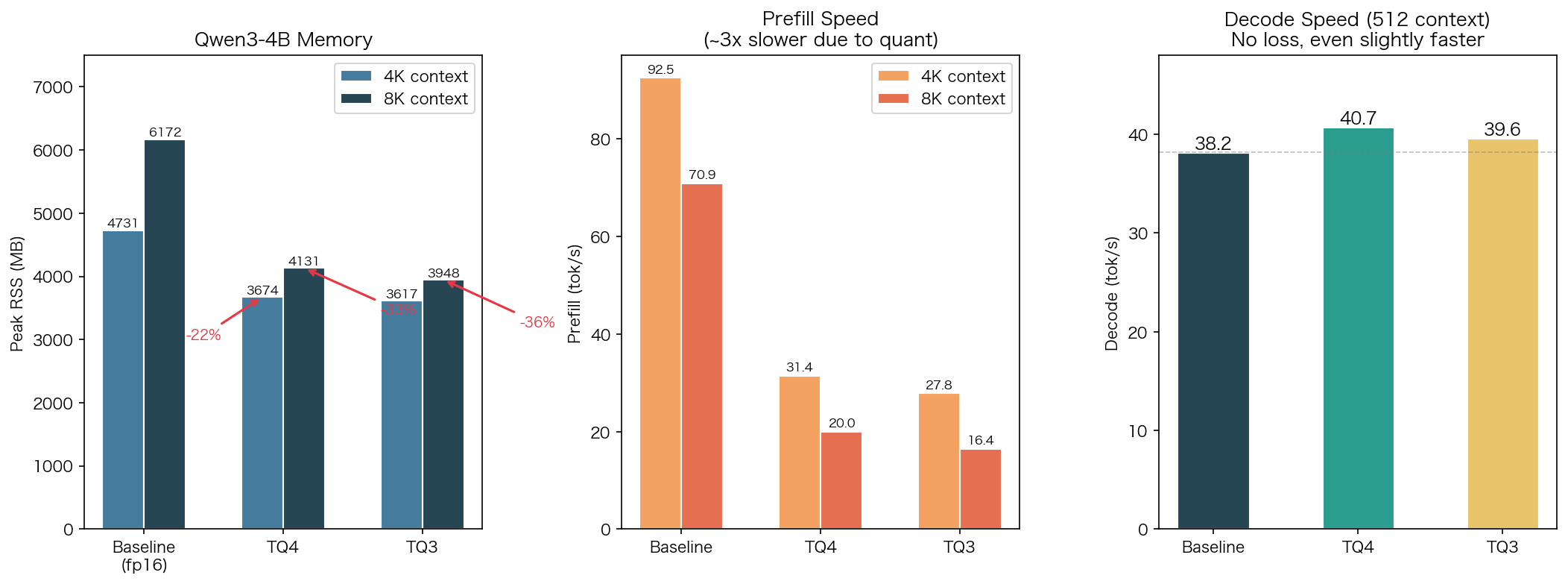
Qwen3-4B 详细数据:
| 上下文 | 指标 | Baseline | INT8 | TQ4 | TQ3 |
|---|---|---|---|---|---|
| 4K | 内存 (MB) | 4,731 | 4,728 | 3,674 (-22%) | 3,617 (-24%) |
| 4K | Prefill (tok/s) | 92.55 | 99.34 | 31.43 | 27.83 |
| 4K | Decode (tok/s) | 40.08 | 40.76 | ~40 | ~40 |
| 8K | 内存 (MB) | 6,172 | 6,008 | 4,131 (-33%) | 3,948 (-36%) |
| 8K | Prefill (tok/s) | 70.86 | 81.65 | 20.01 | 16.44 |
| 8K | Decode (tok/s) | ~40 | 40.35 | ~40 | ~40 |
核心结论:
- 内存节省随上下文长度增大而增大:4K 省 22~24%,8K 省 33~36%,上下文越长优势越大
- Decode 速度完全无损:独立测试 Baseline 38.19、TQ4 40.72、TQ3 39.61 tok/s,量化后反而略快(KV Cache 更小 → 访存更少)
- Prefill 约慢 3~4x:瓶颈在量化计算(WHT + 码本搜索),是在线量化的固有开销
4.3 输出质量
问题:”中国的首都是哪里?”(greedy decoding, max_new_tokens=100)
| 模型 | Config | 输出 |
|---|---|---|
| 4B | Baseline | 中国的首都是北京。 |
| 4B | TQ4 | 中国的首都是北京。 ✅ |
| 4B | TQ3 | 中国的首都是北京。北京位于中国北部……(语义正确但略发散) |
| 0.6B | TQ4 | (输出全是换行符,无有效内容)❌ |
| 0.6B | TQ3 | “中国 中国 中国”……(重复乱码)❌ |
4.4 小模型为什么崩了?
TurboQuant 的数学保证在 0.6B 上仍然成立,但论文隐含了一个前提:模型有足够冗余度来消化量化噪声。
通过实测 KV Cache 数值分布发现了根因:
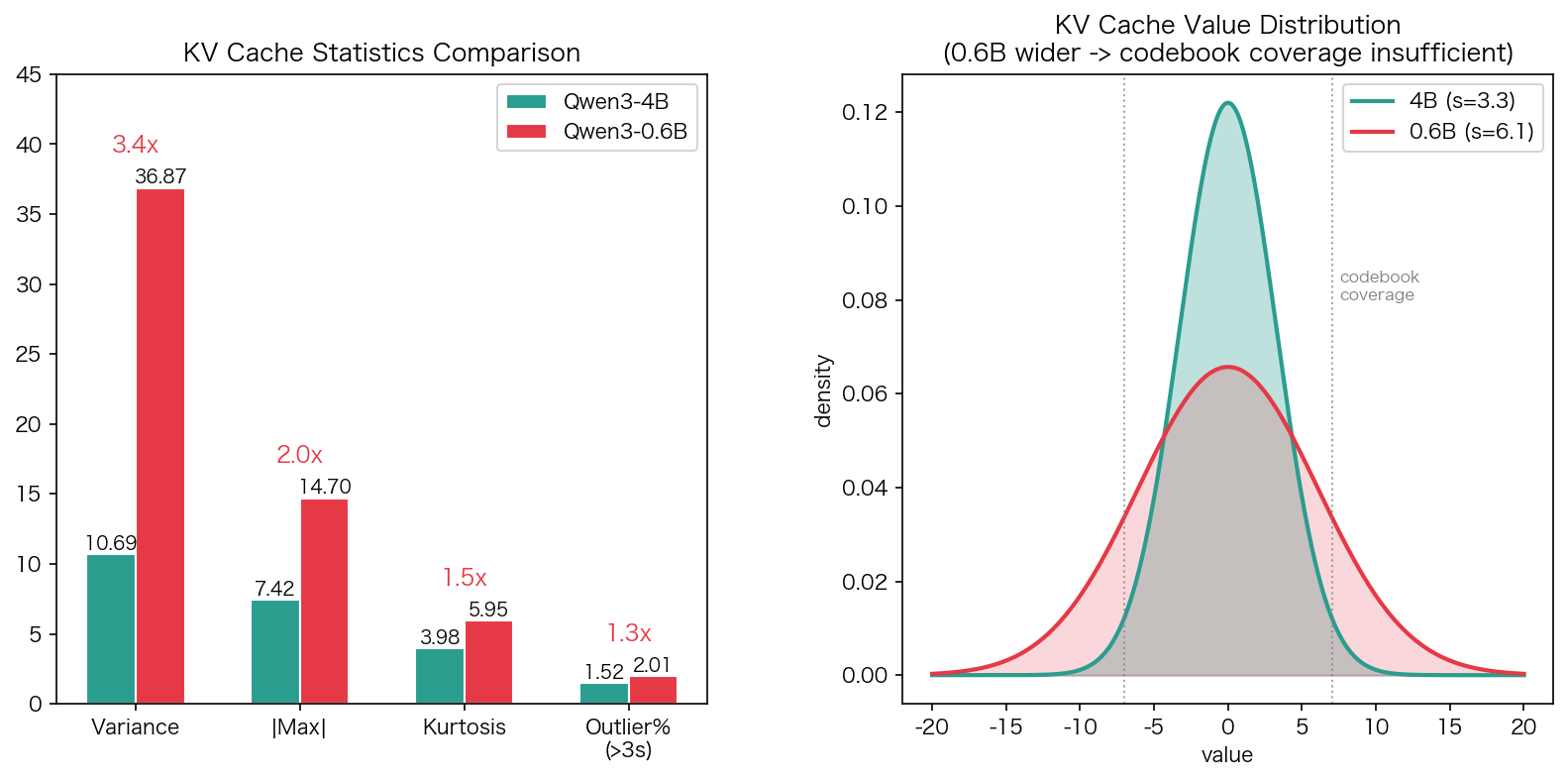
| 指标 | Qwen3-4B | Qwen3-0.6B | 差距 |
|---|---|---|---|
| 方差 | 10.69 | 36.87 | 3.4x |
| 绝对最大值 | 7.42 | 14.70 | 2.0x |
| 峰度 | 3.98 | 5.95 | 1.5x |
| 离群率 (>3σ) | 1.52% | 2.01% | 1.3x |
小模型崩坏的三重原因:
- 绝对误差放大:0.6B 的 KV Cache 方差是 4B 的 3.4x,即使 MSE/Var 比值不变,绝对 MSE 也大 3.4 倍
- 纠错能力不足:0.6B head 更少、layer 更少,每个 KV 值对输出的贡献权重更大,误差无法通过多 head/layer 平均消除
- 误差累积:自回归生成中量化误差通过 attention 传播到后续 token,小模型更难修正
4.5 0.6B 的内存节省
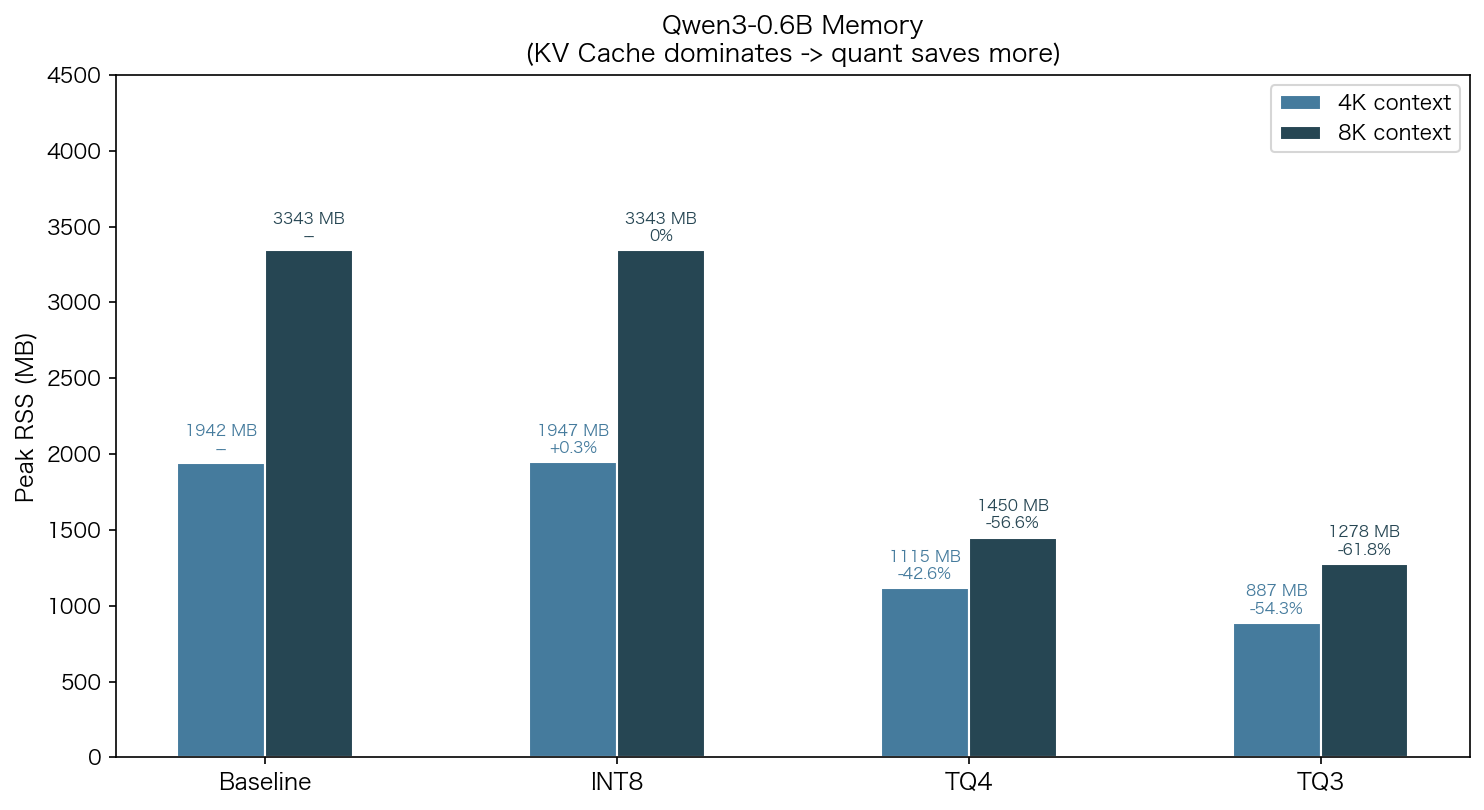
虽然 0.6B 上精度崩坏,但内存压缩本身是有效的——TQ3 在 8K 上下文节省 62% 内存(3343→1278 MB),比 4B 的 36% 节省更多,因为小模型中 KV Cache 占总内存比例更高。
有趣的是,0.6B TQ3 的 decode 速度反而超过 baseline(217.64 vs 170.99 tok/s),因为 KV Cache 压缩后访存带宽需求大幅降低。
4.6 各方案综合对比
综合精度、内存、速度三个维度:
- Baseline:精度和 prefill 最优,但零压缩
- INT8:全面均衡(精度无损 + prefill 更快),但压缩率有限(仅 2x)
- TQ4:在内存节省和 decode 速度上明显优于 INT8,代价是精度下降 20% 和 prefill 变慢 3x
- TQ3:比 TQ4 多省约 3% 内存,但 PPL 从 +20% 跳到 +87%,性价比不高
4.7 实验结论
| 结论 | 详细说明 |
|---|---|
| TQ4 是 4B+ 模型的推荐方案 | PPL +20%,内存 -33%(8K),decode 无损,输出质量良好 |
| TQ3 更极致但需谨慎 | 内存多省 ~3%,但 PPL +87%,需评估具体任务可接受性 |
| 小模型 (<1B) 不适用 | 0.6B 上 TQ4 PPL +638%,TQ3 完全崩坏,建议保持 fp16 |
| Decode 是”免费”的 | 量化后 KV Cache 更小,decode 访存更快,速度甚至略有提升 |
| Prefill 是代价 | WHT + 码本搜索导致 prefill 慢 ~3x,是在线量化的固有开销 |
| 上下文越长越划算 | 4K 省 22%,8K 省 33%,长上下文场景收益更大 |
| INT8 仍是保守首选 | 几乎无损 + prefill 更快,适合对精度要求高的场景 |
使用建议:
模型规模: ≥ 4B → TQ4(推荐) 1-4B → 谨慎评估 < 1B → fp16
场景选择: 长上下文(≥8K)→ TQ4 收益最大 短对话 → INT8 或 fp16
五、总结
TurboQuant 确实是一个有效的 KV Cache 量化方案——理论优雅、实现简洁、不依赖校准数据,在 4B 及以上模型上取得了不错的内存-精度平衡。它和 QuaRot 等基于旋转的量化方法有一定的相似性(都利用正交变换打散离群值),但 TurboQuant 更进一步:利用旋转后分布的可知性来设计信息论最优码本。
但客观来说,它并非银弹。AI 对存储和算力的需求依然庞大且在持续增长——模型在变大、上下文在变长、多模态在普及。TurboQuant 在 KV Cache 这个局部点上提供了一个有效的压缩手段,但和其他量化方法相比,并不构成突破性的代差。真正的存储瓶颈缓解,仍然需要从模型架构、量化算法、硬件协同等多个层面共同推进。
参考
Enjoy Reading This Article?
Here are some more articles you might like to read next: