Claude有多大?从推理速度反推参数量
起因
3 月 26 日,一次 CMS 配置错误让 Anthropic 下一代旗舰模型 Claude Capybara(内部代号 Mythos)意外曝光,Anthropic 随后向 Fortune 杂志确认了它的存在,称其为”我们构建过的最强大模型”。要知道现在的 Opus 4.6 已经是我日常编程的主力工具了,而 Capybara 在 Terminal-Bench 2.0 等编程基准上还要远超 Opus,网络安全领域的漏洞利用能力更是被描述为”远超任何其他 AI 模型”——强到 Anthropic 只敢先给少数网络防御客户测试。
不过能力提升的代价也很直观:Capybara 的推理速度可能只有 Opus 4.6 的 40%,这背后大概率是参数量的大幅增加。这篇文章就是尝试从推理速度反推 Claude 的参数规模——结论是 Opus 4.6 激活参数约 80–110B,总参数约 1.5–2.5T;而 Capybara 激活参数可能在 150–250B,总参数突破 4T。
数据与方法
Anthropic 不公开参数量,但参数量可以从推理速度反推。思路很简单:在 Google Vertex、Amazon Bedrock 这类第三方托管平台上,同一个服务商为所有模型提供的是同一套推理基础设施,没有理由针对某个特定模型故意降速或加速。那么不同模型之间的吞吐量差异,反映的就是模型本身参数规模的差异。
所以我的做法是:在同一平台上收集一批参数量已知的开源模型(DeepSeek、GLM、Kimi、Llama 等)的推理速度,建立参数和速度的对应关系,再用这个关系去反推 Claude 的参数量。
Google Vertex 平台
| 模型 | Total Params | Active Params | Architecture | Precision | Throughput (TPS) | Latency |
|---|---|---|---|---|---|---|
| DeepSeek V3.1 | 685B | 37B | MoE | FP8 | 110 | 0.78s |
| GLM-4.7 | 355B | 32B | MoE | FP8 | 108 | 0.78s |
| Kimi K2 Thinking | 1.04T | 32B | MoE | FP4 | 206.5 | 0.37s |
| MiniMax M2 | 230B | 10B | MoE | FP8 | 131.5 | 3.25s |
| GPT-OSS-120B | 117B | 5.1B | MoE | FP8 | 297 | 0.33s |
| GPT-OSS-20B | 21B | 3.6B | MoE | FP8 | 267 | 0.30s |
| Llama 3.3 70B | 70B | 70B | Dense | FP8 | 61 | 0.20s |
| Claude Opus 4.6 | ? | ? | ? | FP8 | 41 | 1.37s |
| Claude Sonnet 4.6 | ? | ? | ? | FP8 | 46 | 1.35s |
Amazon Bedrock 平台
| 模型 | Total Params | Active Params | Architecture | Throughput (TPS) | Latency |
|---|---|---|---|---|---|
| GPT-OSS-20B | 21B | 3.6B | MoE | 210 | 1.02s |
| GPT-OSS-120B | 117B | 5.1B | MoE | 171 | 1.32s |
| Claude Opus 4.6 | ? | ? | ? | 35 | 2.49s |
| Claude Sonnet 4.6 | ? | ? | ? | 39 | 1.99s |
Bedrock 上 Claude 的速度比 Vertex 慢约 15%,这是 provider 端的队列策略差异,不影响模型本身的判断。后续分析以 Vertex 数据为准。
推导逻辑
LLM 的 Decode 阶段是逐 token 自回归生成,瓶颈在显存带宽(memory-bound)。理论吞吐量满足:
TPS ≈ Memory_Bandwidth / (Active_Params × Bytes_Per_Param)
→ Active_Params × TPS × Precision_Factor ≈ Constant
简单说:在同一硬件平台、同一量化精度下,激活参数 × 吞吐量 应该近似等于一个常数。如果这个常数靠谱,用它除以 Claude 的 TPS,就能算出 Claude 的激活参数。
先用开源模型验证一下。设 FP8 factor = 1.0,FP4 factor = 0.5,归一化后的乘积:
| 模型 | Active | TPS | Raw Product | Precision | Normalized |
|---|---|---|---|---|---|
| DeepSeek V3.1 | 37B | 110 | 4,070 | FP8 | 4,070 |
| GLM-4.7 | 32B | 108 | 3,456 | FP8 | 3,456 |
| Kimi K2 Thinking | 32B | 206.5 | 6,608 | FP4 | 3,304 |
| MiniMax M2 | 10B | 131.5 | 1,315 | FP8 | 1,315 |
| GPT-OSS-120B | 5.1B | 297 | 1,515 | FP8 | 1,515 |
| GPT-OSS-20B | 3.6B | 267 | 961 | FP8 | 961 |
| Llama 3.3 70B | 70B | 61 | 4,270 | FP8 | 4,270 |
几个观察:
- 大模型的乘积比较稳定:Llama 3.3 70B (4,270)、DeepSeek (4,070)、GLM (3,456)、Kimi FP4 归一化后 (3,304),四者都在 3,300–4,300 区间。这说明 30B+ 激活参数的模型(不管是 Dense 还是 MoE),decode 确实是 memory-bound 主导,乘积近似常数的假设成立。
- Llama 3.3 70B 是最有价值的参考点:它是 Dense 架构,Active = Total = 70B,没有 MoE 的 expert routing 开销,也没有激活参数不确定性的问题。而且 70B 正好接近 Claude 的预测区间,作为锚点比 30B 级别的 MoE 模型更直接。
- 小模型的乘积明显偏低:GPT-OSS-120B (1,515)、GPT-OSS-20B (961)、MiniMax M2 (1,315),active 越小乘积越低。这是因为小模型的 compute-bound 占比更高,达不到 memory-bound 的理论上限——换句话说,小模型跑得比”应该”的速度慢,乘积就偏低了。
- Kimi K2 Thinking 的原始乘积 (6,608) 远高于 FP8 模型,按 FP4 归一化后落回 3,304,和 DeepSeek、GLM 一个区间。这说明 Kimi 大概率用了 FP4 或混合精度部署。
Claude 的激活参数预计在 70B+(后面会算出来),属于大模型范畴,用大模型的乘积作为基准是合理的。基准常数取 3,300–4,300 这个区间,中心值约 3,800。
Claude 激活参数计算
原始反推
用基准常数的范围来算:
Opus Active ≈ 3,300~4,300 / 41 ≈ 80~105B
Sonnet Active ≈ 3,300~4,300 / 46 ≈ 72~93B
Thinking Tokens
Vertex 标注的 TPS “Includes reasoning tokens”。不过 thinking tokens 的生成和普通 tokens 一样,都是 decode 阶段的自回归操作,计算模式完全相同。所以 TPS 已经反映了模型的真实 decode 性能,不需要额外修正。
Context Length 修正
Opus/Sonnet 支持 1M context,KV cache 和 attention 的开销比 128K 模型多约 3% 的带宽消耗,小幅上调:
Opus ≈ (3,300~4,300 / 41) × 1.03 ≈ 83~108B
Sonnet ≈ (3,300~4,300 / 46) × 1.03 ≈ 74~96B
综合两个平台的数据:
- Opus 激活参数: 80–110B(中心值约 95B)
- Sonnet 激活参数: 70–95B(中心值约 83B)
值得注意的是,Llama 3.3 70B 的 Dense 70B 在 Vertex 上只有 61 TPS,而 Claude Opus 只有 41 TPS——如果 Claude 也是 Dense 架构,那它的参数至少在 70 × (61/41) ≈ 104B。但 Claude 大概率是 MoE(从 Opus 和 Sonnet 速度接近但能力差距明显来看),MoE 的 routing overhead 会让实际 TPS 略低于纯 memory-bound 预测,所以激活参数的真实值可能在这个范围的中下部。
总参数估计
MoE 架构的 Total / Active ratio 在不同模型之间差异很大,看一下开源模型的数据:
| 模型 | Active | Total | Ratio |
|---|---|---|---|
| GPT-OSS-20B | 3.6B | 21B | 5.8x |
| GLM-4.7 | 32B | 355B | 11.1x |
| DeepSeek V3.1 | 37B | 685B | 18.5x |
| MiniMax M2 | 10B | 230B | 23x |
| Kimi K2 | 32B | 1.04T | 32.5x |
这个 ratio 没有简单的规律——同样是 32B 激活参数,GLM 取 11x 而 Kimi 取 32.5x,差了 3 倍。ratio 的大小更多取决于各家的设计选择:expert 数量、expert 粒度、是否共享 expert 等等,不能简单地从激活参数推断。
不过可以缩小范围。从工程实践看,ratio 的主流区间在 10x–25x 之间(Kimi 的 32.5x 属于比较极端的设计)。以 Opus 80–110B 的激活参数为基础:
- 取保守的 15x:Total ≈ 1.2–1.7T
- 取中间的 20x:Total ≈ 1.6–2.2T
- 取激进的 25x:Total ≈ 2.0–2.8T
考虑到 Anthropic 的工程风格偏稳健,不太可能走 Kimi 那种极端路线,Opus 4.6 的总参数大概在 1.5–2.5T 这个量级,2T 附近是一个合理的中心估计。Sonnet 4.6 则略小,大概在 1.0–2.0T。
Capybara 参数预测
泄露信息显示 Capybara 定位是超越 Opus 的下一代旗舰,在编程(Terminal-Bench 2.0 新纪录)、推理和网络安全方面都有大幅提升,目前仅对少数”网络防御”方向的客户开放早期测试。
如果 Opus 4.6 的激活参数约 95B、总参数约 2T,那 Capybara 有多大?
最直接的线索是推理速度。泄露信息暗示 Capybara 的 TPS 约为 Opus 的 40%,也就是大约 16–17 TPS。用同样的反推方法:
Capybara Active ≈ 3,800 / 16.5 ≈ 230B
当然这个估计的不确定性更大——Capybara 可能用了不同的量化精度、不同的硬件集群、甚至不同的架构设计。但数量级上,激活参数 150–250B、总参数 4–6T 是一个合理的推测范围。
这也解释了为什么 Anthropic 选择先给少数客户测试——这个规模的模型,推理成本不是一般的高。
不确定性
需要强调的是,Capybara 的预测比 Opus 的估计多了一层不确定性。Opus 的数据至少能从两个平台交叉验证,而 Capybara 目前只有泄露信息中”速度约为 Opus 40%”这一个数据点,且 Anthropic 完全可能在架构上做了创新(比如更激进的量化、混合精度、或者全新的 attention 机制),使得参数-速度的对应关系发生变化。
结论
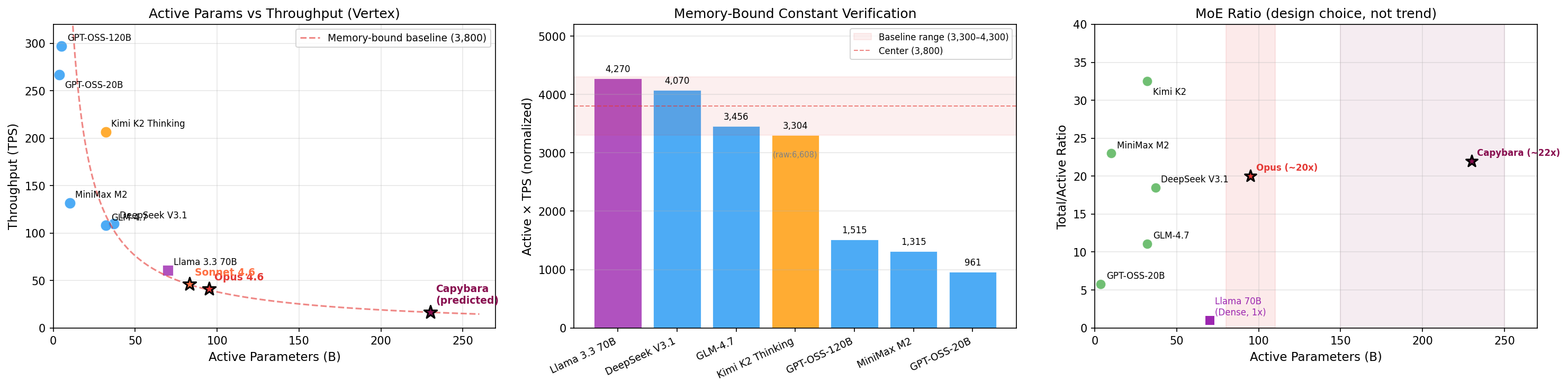 左:激活参数与吞吐量的关系,红色虚线为 memory-bound 理论曲线;中:各模型的 Active × TPS 乘积验证;右:MoE 模型的 Total/Active Ratio 分布。
左:激活参数与吞吐量的关系,红色虚线为 memory-bound 理论曲线;中:各模型的 Active × TPS 乘积验证;右:MoE 模型的 Total/Active Ratio 分布。
通过收集 Google Vertex 平台上多款开源模型(包括 Dense 架构的 Llama 3.3 70B 和多款 MoE 模型)的推理速度,验证了 memory-bound 条件下”激活参数 × TPS ≈ 常数”的关系在大模型上成立。用这个关系反推 Claude 的参数量:Opus 4.6 的激活参数约 80–110B,总参数约 1.5–2.5T;Sonnet 4.6 略小,激活参数约 70–95B,总参数约 1.0–2.0T。两者都采用 FP8 量化的 MoE 架构。
至于下一代的 Capybara,如果泄露的速度数据可信,其激活参数可能在 150–250B 区间,总参数有望突破 4T——这也直接解释了它为什么这么慢。当然,这些数字本身的误差不小(基准常数就有约 ±15% 的波动),对 Capybara 的推测更是多了一层假设,权当一个数量级的参考。
说实话,作为一个每天都在用 Opus 4.6 写代码的人,我很难想象还能比现在强多少。但如果 Capybara 真的能兑现泄露信息里描述的那些能力,那 AI 辅助编程这件事可能又要翻一个台阶了。期待它正式开放的那天。
Enjoy Reading This Article?
Here are some more articles you might like to read next: