MNN支持Eagle3
大语言模型(LLM)端侧推理的性能指标主要是看Prefill和Decode的性能,其中Prefill能够反应首字延迟,Decode能够反应生成速度。在端侧环境下,使用GPU或者NPU能够提升Prefill的速度,降低首字延迟。但是对于Decode速度,这些加速硬件都没有效果。因为Decode过程受限于内存带宽,而端侧设备由于功耗和芯片面积的限制,内存带宽比较受限。因此,提升Decode速度最有效的方法就是投机解码,而 Eagle3 是目前最前沿的方案之一。本文将分享 MNN 适配与优化 Eagle3 的完整实践记录。
推理
Eagle3 会训练出一个约等于模型一层 + 32K大小的lm_head作为草稿模型,在生成过程中会让草稿模型生成出多个草稿Token。然后让主模型“一次性”验证这些草稿,而不是像传统自回归那样逐个token生成。减少了对主模型的调用次数,从而实现了推理加速。
整个推理流程可以分解为以下几个关键步骤:
第一步:初始化与上下文处理
- 输入处理:当用户输入一个提示(Prompt)时,主模型会像标准推理一样,对整个提示进行编码和处理,生成初始的键/值缓存(KV Cache)。这是后续所有生成工作的基础。
- 生成第一个Token:目标模型(Qwen2)基于初始的KV Cache,生成第一个Token。这个步骤是无法“推测”的,必须由主模型完成。
第二步:Eagle3 生成草稿Token
- 获取上下文:Eagle3模型接收目标模型生成的最新一个Token作为输入,并获得主模型的3层中间变量(hidden_states)。
- 并行生成草稿:Eagle3模型利用其轻量的结构,以自回归的方式快速、并行地生成K个候选Token(草稿)。
- 草稿树结构:在这个过程中,Eagle3内部会维护一个“草稿树”。每个节点代表一个生成的草稿Token。这种树状结构是为了在更复杂的推测解码中处理多个候选序列。
第三步:目标模型批量验证
- 准备输入:将Eagle3生成的K个草稿Token与前文的真实Token拼接在一起,形成一个完整的序列。
- 一次性验证:主模型接收这个拼接后的序列,并进行一次前向传播(Forward)。由于输入的序列长度为
(1 + K),Qwen2会一次性地计算出这(1 + K)个位置的概率分布。 - 路径选择:接下来,系统会逐一比对Eagle3生成的草稿Token和主模型验证后的结果,如果验证一致则接受否则拒绝;从验证接受的草稿树中接受路径最长的分支作为最终的输出。
第四步:接受或拒绝并开启新一轮循环
- 更新输出和KV Cache:将未被接受的token的KV Cache删除掉,并将接受token的KV Cache按照顺序排列。
- 循环:回到第二步,让草稿模型基于当前最新的Token,再次生成新的草稿,重复整个“推测-验证”的循环,直到生成满足长度要求或遇到终止符。
这个流程有效地将多次主模型的推理,替换为“多次小模型推理 + 一次主模型验证”,总的访存大小小于单纯的主模型推理。
比如假设模型的参数是2B, 草稿模型大小为0.1B,我们单次生成3个草稿且平均能够接受1个,则访存量如下:
- 标准解码:2B * 2 = 4B
- 投机解码:,则总访存大小为2B + 0.1B * 3 = 2.3B
投机解码的访存量为标准解码的57.5%,有效降低了带宽需求,提升模型Decode速度。
Eagle3的优势在于其在比较小的参数情况下能够做到比较高的接受率,因此我们选择使用Eagle3。
MNN中的Eagle3推理
为了在MNN C++推理引擎中高效地实现Eagle3的推测性解码(Speculative Decoding)算法,我们设计并实现了一套完整的端到端流程。我们将复杂的草稿Token生成与管理的逻辑,抽象成了一个独立的、可复用的 TokenTree 类,极大地简化了主流程的复杂度,并增强了代码的可维护性。
核心设计:TokenTree 类
在推测性解码中,草稿模型需要生成一个包含多条候选序列的“树”。管理这棵树的生长、剪枝和信息提取是整个流程中最复杂的部分。为了解决这个问题,我们创建了 TokenTree 类,它封装了以下所有核心功能:
- 节点管理:内部使用
TokenTreeNode结构体来表示树中的每一个Token,清晰地存储了Token ID、对数概率、深度以及父子关系。 - 树的初始化与生长:
-
init(): 接收第一轮Top-K预测结果,初始化树的第一层节点。 -
grow(): 在每一轮迭代中,接收当前所有叶子节点的Top-K预测结果,生成新的候选节点,并根据累积概率进行排序和剪枝,仅保留最优的K个候选者作为新的叶子节点。
-
- 注意力掩码(Attention Mask)管理:在树生长的过程中,
TokenTree会同步地、高效地计算和更新下一轮迭代所需的注意力掩码,确保每个Token只能注意到其路径上的祖先节点。 - 最终输出打包:
-
finalize(): 当树生长到预设深度后,该方法会整理所有候选的草稿Token,并生成主模型进行批量验证所需的所有输入,包括:-
draftTokens: 扁平化后的草稿Token序列。 -
positionIds: 每个草稿Token在序列中的正确位置ID。 -
attentionMask: 供主模型使用的、符合树状结构的注意力掩码。 -
retrieveIndices: 用于从主模型输出中快速回溯和验证最佳路径的索引列表。
-
-
EagleGeneration:清晰的主流程
通过将复杂的树状结构管理逻辑剥离到 TokenTree 中,主流程类 EagleGeneration 的职责变得非常清晰和线性:
- 调用草稿模型:执行Eagle模型的前向计算,获取logits。
- 驱动TokenTree:将logits结果喂给
TokenTree实例,调用其grow()方法来发展草稿。 - 获取验证数据:当草稿生成完毕,调用
TokenTree的finalize()方法,一键获取打包好的、用于主模型验证的所有输入张量(Tensors)。 - 执行主模型验证:调用主模型进行一次高效的批量前向推理。
- 结果解析与循环:根据验证结果,确定接受的Token数量,并开启下一轮的草稿生成循环。
训练
Eagle3 训练特点
Eagle3的出色效果其实源自于其训练过程的设计。在Eagle3之前,像EAGLE这样的草稿模型存在一个普遍问题:
- 间接的预测目标:模型被训练去预测主模型的中间层特征 (feature),而非直接预测最终的词元 (token)。这是一个额外且不必要的约束,限制了模型的表达能力。
- 训练与推理的不一致性:在训练时,模型每一步的输入都是来自目标模型的“完美”特征;但在推理时,模型却必须依赖自己上一步生成的、“不完美”的预测结果作为输入。这种不一致导致误差会像滚雪球一样累积,使得草稿序列在第二个、第三个词元之后的质量急剧下降,严重影响了最终的加速效果。
Eagle3通过以下两项紧密结合的改进,彻底解决了上述问题:
1. 摆脱特征预测约束,融合多层级特征
首先,EAGLE-3完全摒弃了预测中间特征的旧范式,直接以预测最终的Token分布为目标。更重要的是,它不再仅仅依赖目标模型的顶层特征,而是创新性地融合了来自低、中、高不同层级的特征信息。通过一个简单的全连接层(FC)进行信息压缩,为草稿模型提供了远比以往更丰富、更全面的语义输入。
2. 引入“训练时测试” (TTT),解决误差累积
这是Eagle3训练方法中最核心的创新。其思想是在训练阶段就完整地模拟推理时的多步生成过程:
- 闭环反馈:当草稿模型在训练中生成第一个预测输出后,该输出会立即被用作下一轮预测的输入,而不是使用来自目标模型的“标准答案”。
- 模拟真实环境:这个过程会模拟性地持续多步,并动态调整注意力掩码(Attention Mask),让模型在训练中就“演练”如何基于自己的预测进行连贯的思考和生成。
这种“自产自销”的闭环训练方式,迫使模型学会了如何处理和修正自身预测中可能存在的微小偏差。它从根本上解决了训练与推理不一致的问题,使得训练出的草稿模型变得异常鲁棒。
总结而言,通过“训练时测试”机制,我们训练的中文Eagle3模型不仅学习目标模型的输出,更重要的是学会了如何在其自身的输出序列上进行稳定、高质量的连续生成。这使得模型在实际推理中能够产出更长、接受率更高的草稿序列,从而为实现业界领先的端侧推理加速比奠定了坚实的基础。
好的,这是一个补充和润色后的段落,可以无缝地放入你的技术文章中。
训练框架选择:SpecForge
在启动Eagle3的训练任务时,选择一个高效、灵活且易于扩展的训练框架至关重要。
虽然Eagle官方提供了原始的训练实现代码,为我们理解其核心算法提供了宝贵的参考,但在实际工程应用中,我们发现它存在一些局限性。例如,其原生支持的模型种类有限,当我们需要将其应用于像Qwen2这样的新模型时,往往需要投入大量的精力进行代码适配和修改,这在一定程度上拖慢了研发和迭代的速度。
为了解决这些挑战,我们最终选择了由SGLang团队精心打造的 SpecForge 框架。SpecForge是一个专为推测性解码(Speculative Decoding)草稿模型设计的训练库,它完美地契合了我们的项目需求:
-
广泛的模型支持:SpecForge拥有开箱即用的特性,无缝支持包括Llama系列、Qwen系列、GPT-OSS在内的众多主流开源大模型架构。这意味着我们可以将精力完全集中在模型训练和数据优化上,而不是花费在繁琐的底层代码适配工作上。
-
卓越的易用性:该框架提供了高度封装和用户友好的API。它将复杂的“训练时测试 (TTT)”逻辑、动态注意力掩码管理等核心环节进行了优雅的抽象。开发者只需通过简单的配置,就能启动一个完整的Eagle3训练流程,极大地降低了上手门槛。另外,它还支持在AMD的显卡上进行训练,这让我在AMD环境下可以轻松上手。
-
社区活跃与维护:作为SGLang生态的一部分,SpecForge拥有活跃的社区支持和持续的更新维护,确保了框架的稳定性和前沿性。
训练数据构造:EagleChat
在基于SpecForge框架对Qwen3系列进行Eagle3训练的初期,我们主要使用了社区通用的 ShareGPT 和 UltraChat 数据集。然而,在实际测试中,我们发现这种通用的数据配比在特定场景下存在明显的短板,主要体现在:
- 中文场景“水土不服”:原有数据集以英文为主,导致草稿模型在中文语境下的接受率极低,几乎无法提供加速。
- 接受率低:即使在英文环境下测试,接受率也远低于官方给出的Llama模型。
为了解决上述问题,我们构建了一个高质量的中英双语对话数据集——EagleChat,并对其进行了详尽的消融实验。
数据集构成:混合与平衡
EagleChat 旨在成为一个能显著增强 LLM(特别是像 EAGLE 这样的草稿模型)综合对话能力的优质语料库。我们采用混合策略,将 smoltalk-chinese 引入到现有的 ShareGPT 和 UltraChat 中,不仅补足了中文能力,还强化了思维链(CoT)推理能力。
最终构建的数据集包含超过 100万 条高质量对话数据,具体分布如下:
| 数据来源 (Source Dataset) | 对话数量 (Number of Conversations) | 作用与特点 |
|---|---|---|
| ShareGPT | 120,675 | 高质量的用户真实交互数据,覆盖多领域 |
| UltraChat | 207,865 | 大规模合成对话数据,增强通用指令遵循能力 |
| smoltalk-chinese | 710,564 | 核心增量,专注于中文思维链与推理,大幅提升中文及逻辑能力 |
| Total | 1,039,104 | EagleChat 总量 |
所有数据均经过统一格式化清洗和随机打乱,以保证训练的稳定性。
效果验证:用数据说话
为了验证 EagleChat 的有效性,我们使用 Qwen3-4B-Instruct 作为基座模型,分别使用 EagleChat、ShareGPT 和 UltraChat 训练了三个版本的 Eagle3 草稿模型,并在多个权威基准测试上对比了它们的平均接受长度(Acceptance Length, acc_length)。
注:
acc_length越高,意味着推理加速效果越好。
核心实验结果如下表所示:
| Benchmark | 任务类型 | EagleChat (Ours) | ShareGPT | UltraChat | 提升幅度 (%) |
|---|---|---|---|---|---|
| C-Eval (Draft=8) | 中文综合 | 2.03 | 1.17 | 1.08 | +73.38% 🚀 |
| CMMLU (Draft=8) | 中文综合 | 2.02 | 1.18 | 1.08 | +71.65% 🚀 |
| Math500 (Draft=8) | 数学推理 | 2.46 | 1.95 | 1.70 | +26.14% |
| GSM8K (Draft=8) | 数学推理 | 2.38 | 1.93 | 1.81 | +23.35% |
| HumanEval (Draft=8) | 代码生成 | 2.49 | 2.10 | 1.94 | +18.61% |
| MT-Bench (Draft=8) | 通用能力 | 1.90 | 1.65 | 1.61 | +15.05% |
(Draft=N 表示主模型每次验证 N 个 token)
结果分析:
- 中文能力爆发式增长:在 C-Eval 和 CMMLU 等中文基准测试中,EagleChat 训练的模型相比 Baseline 取得了 超过 60%-70% 的巨大提升。这直接证明了引入
smoltalk-chinese对于解决“中文失语”问题的决定性作用。 - 逻辑推理显著增强:在 GSM8K 和 Math500 等数学任务上,接受长度提升了约 25%。这意味着草稿模型不仅学会了说话,还学会了模仿主模型的推理步骤。
- 全面优于基线:即使在通用的 MT-Bench 和代码任务上,EagleChat 也保持了 15% 左右的稳定优势。
可视化对比(Draft Tokens = 4 vs 8):
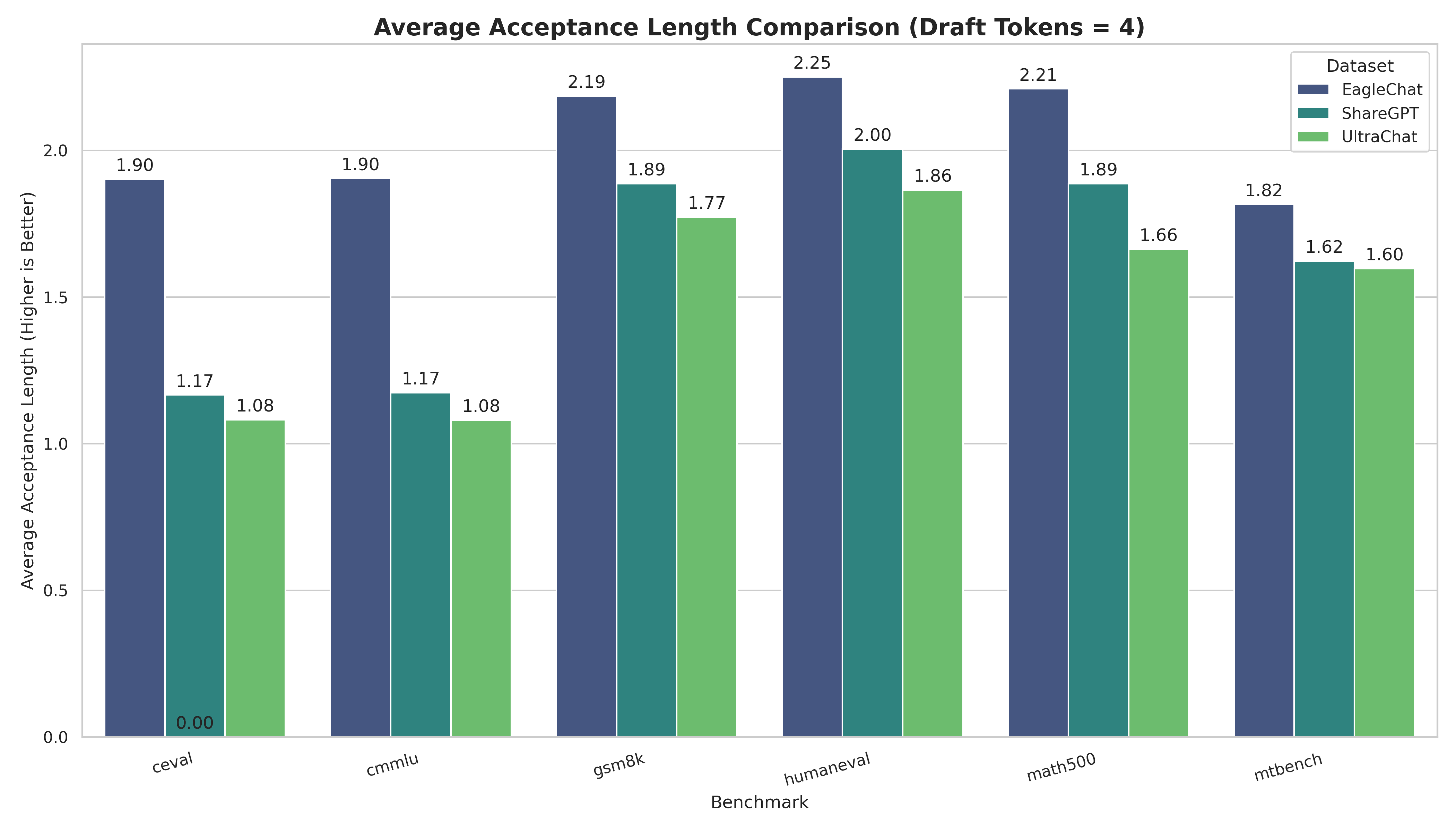
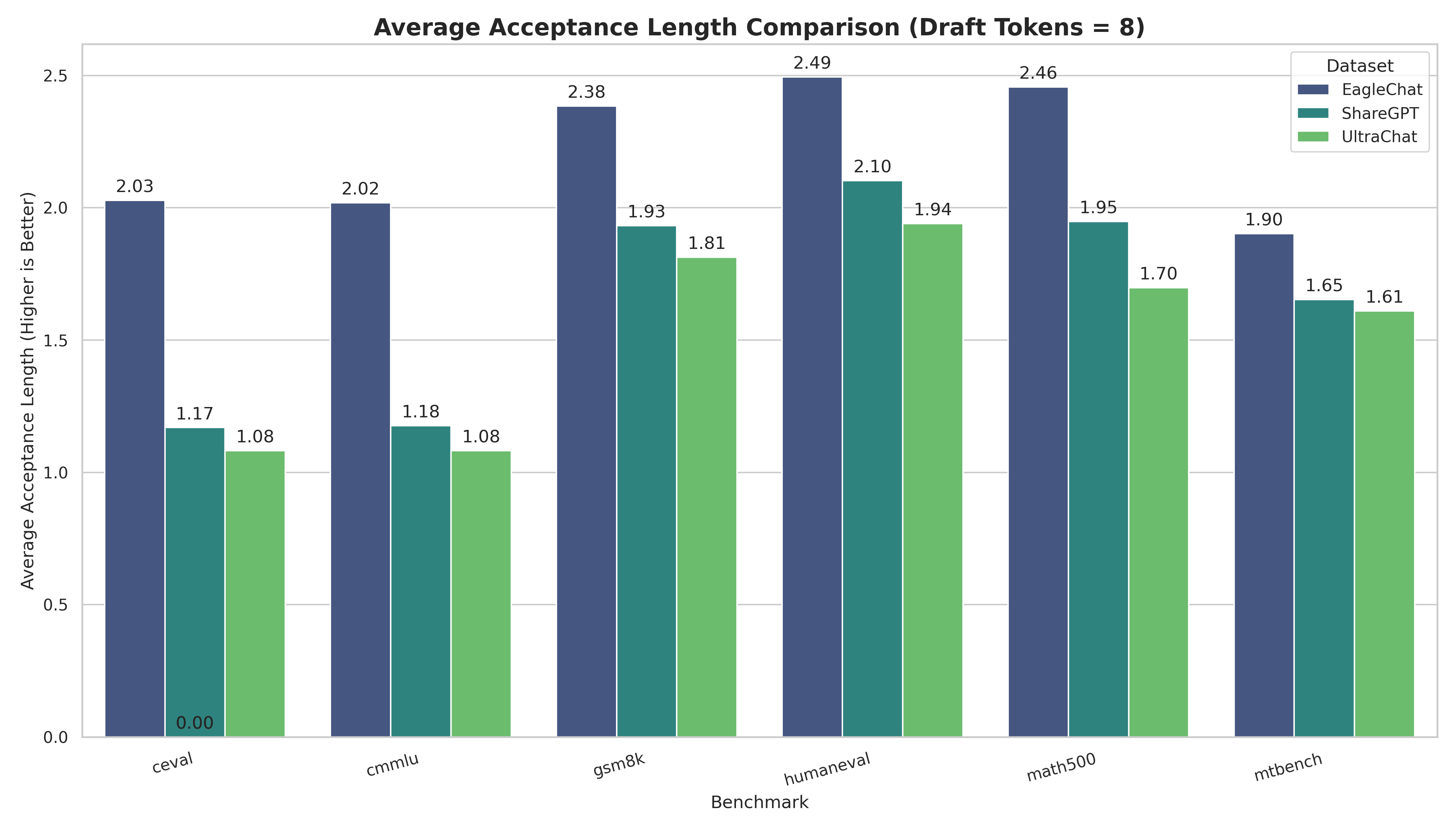
实验数据可以看出:高质量、混合配比的 EagleChat 数据集,是训练高性能、支持中文 Eagle3 模型的关键所在。
工程适配:改进 SpecForge
在训练过程中发现了SpecForge中存在一些问题并对其进行修复和改善,并将修改贡献回了 SpecForge 社区。
- 在AMD环境训练时 triton kernel的 num_warps 设置错误 PR #259
- 增加EagleChat数据集,并修复中文数据乱码问题 PR #266;
- 增加中文的benchmark,以测试在中文数据集上的接受率 PR #267
测试
将训练好的模型部署到真实的端侧设备上,是我们整个工作的最后一步,也是检验成果的关键环节。在测试过程中我们发现,理论上的最优配置与实际应用场景之间存在差异,尤其是在算力受限的设备上,对草稿数量的调优至关重要。
验证开销的权衡
在服务端或拥有强大GPU的设备上,一次性验证多个草稿词元(Token)的开销相对较小。然而,在端侧设备,尤其是CPU上运行时,我们发现验证(Verification)本身并非没有开销。
当草稿树设置得过宽或过深(即一次性生成大量草稿词元)时,主模型进行批量验证的计算量会相应增大。如果这些草稿的接受率不够高,那么这种“大批量验证”的开销甚至可能会抵消掉推测性解码带来的收益,导致整体加速比不升反降。
最佳草稿数量配置
经过多轮实验,我们发现在端侧CPU这类算力受限的场景下,并非草稿数量越多越好。更少的草稿数量意味着更低的验证开销和更高的平均接受率,反而能带来更稳定的加速效果。
我们推荐的配置是单次生成3个或7个草稿词元(Draft Tokens)。这样,连同上下文的第一个词元,主模型单次仅需验证4个或8个词元。这个数量在当前主流的端侧硬件上达到了草稿生成开销、批量验证开销与高接受率之间的最佳平衡。
加速效果实测
在采用上述优化配置后,我们在端侧设备上取得了显著的加速效果。
- 场景表现差异:
- 在英文和编程类任务中,由于其语言结构相对固定,草稿模型的接受率最高。
- 中文场景的接受率略低,这与中文语言的复杂性和灵活性有关,但依然表现出色。
- 量化加速结果:
- 平均加速效果:综合各类任务,解码(Decode)阶段的平均速度提升了约 50%。
- 峰值加速效果:在接受率较高的最佳场景下(如生成结构化代码或固定格式的英文文本),加速比可高达 100%,即实现了推理速度的翻倍。
这一结果证明,经过精心的训练和参数调优,Eagle3草稿模型能够在端侧设备上带来稳定且可观的性能提升。
搞定!以及“开箱即用”的模型
好了,以上就是MNN支持Eagle3的全过程。
我们从重构 C++ 代码开始,给模型搭配了一套中英混合的EagleChat 数据集,同时给 SpecForge 社区“添砖加瓦”修了 Bug,最后在端侧设备上简单测试了一下性能,总算把能踩的坑都踩了一遍。
我们把最终训练好的“成品”——也就是适配了 Qwen3 的 Eagle3 模型——都放在下面了,欢迎大家下载试玩,或者给我们提 Issue 一起交流。
-
Hugging Face (抱抱脸)传送门: https://huggingface.co/collections/taobao-mnn/eagle3
-
魔搭 (ModelScope) 传送门: https://modelscope.cn/collections/Eagle3-408e79eec8b441
就这样,祝大家玩得开心!
Enjoy Reading This Article?
Here are some more articles you might like to read next: