深入 gpt-oss-20b 架构:MNN 移动端性能实践
在 OpenAI 开源 gpt-oss-20b 模型之后,MNN 迅速完成了对这个 20B 参数大语言模型的高效适配,成功将其带到移动端。实测结果表明,该模型不仅知识渊博、推理能力不凡,并且在手机上也能实现令人印象深刻的运行速度。
智力测试:gpt-oss-20b vs. Qwen3-30B-A3B-Thinking-2507
为了深入探究 gpt-oss-20b 的能力边界,我们将其与同样强大的 Qwen3-30B-A3B-Thinking-2507 模型进行了一场横向对比评测。
测试环境说明
两款模型均使用 MNN 的 4-bit HQQ 方法进行量化,并在 Mac M3 Pro 上通过 MNN 框架进行测试。我们采用了各模型官方推荐的采样配置,并使用 Gemini 1.5 Pro 生成了一系列涵盖数学、物理、逻辑和常识推理的测试问题。
测试题目如下:
9.11 和 9.9 哪个大?
有一架飞机,停在一个和跑道一样长、一样宽的巨型跑步机上。跑步机的系统被设定为:无论飞机机轮的速度是多少,它都会以完全相同的速度向相反方向>运动,从而抵消机轮的转动。请问,这架飞机能否成功起飞?
你有一个完全密闭、内部是完美真空、并且100%不透光的坚固箱子。你在箱子里的天平上称量这个箱子。然后,你打开了箱子里的一支手电筒。请问,当手>电筒亮着时,天平显示的重量会比之前更重、更轻,还是完全一样?
你有两根不均匀的绳子,每根绳子从一头烧到另一头都正好需要1个小时。所谓不均匀,是指绳子可能前半段10分钟就烧完了,后半段却烧了50分钟。现在,
只用这两根绳子和一个打火机,你如何精确地计时45分钟?
I want to cool down a sealed room, so I leave my refrigerator door open inside it. Will the room's overall temperature eventually rise, lower, or stay the same?
If all the people on Earth gathered in one place and all jumped at the exact same time, what would happen to the Earth? Would its orbit be altered?
📊 测试结果一览
| 测试项目 | gpt-oss-20b | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|
| 数值比较 (9.11 vs 9.9) | ✅ 正确 (认为9.9更大) | ✅ 正确 (认为9.9更大) |
| 物理推理 (跑步机与飞机) | ❌ 错误 (认为不会起飞) | ✅ 正确 (能够起飞) |
| 高级物理 (密闭箱中的光) | ✅ 正确 (E=mc²) | ❌ 错误 (忽略质能等价) |
| 逻辑推理 (烧绳计时45分钟) | ✅ 正确 (标准解法) | ✅ 正确 (标准解法) |
| 热力学 (敞开的冰箱) | ✅ 正确 (热力学第二定律) | ✅ 正确 (直觉误判) |
| 宏观力学 (全球人同时跳) | ✅ 正确 (量化分析) | ✅ 正确 (定性分析) |
详细测试结果
🎯 关键洞察
通过这场对决,两个模型展现出截然不同的“智能画像”:
-
gpt-oss-20b:知识渊博的“检索型专家” 它在需要精确、深入专业知识的领域表现卓越。例如,在“密闭箱中的光”问题上,它能准确调用质能等价性(E=mc²)这一高级物理知识,给出理论严谨的回答。这表明其庞大的参数量有效地存储了丰富的世界知识。
-
Qwen3-30B-A3B-Thinking-2507:逻辑缜密的“推理型思考者” 它在需要多步推理、理解相对关系和进行科学计算的场景中更胜一筹。例如,在“跑步机上的飞机”,它能摆脱直觉误导,运用正确的物理原理和量化分析来解决问题。
结论:gpt-oss-20b 强大的知识储备使其在“是什么”的问题上表现突出,而 Qwen3-30B-A3B-Thinking-2507 则在“为什么”和“如何做”的问题上展现了更强的逻辑推理能力。
架构深度解析
gpt-oss-20b 的独特性能源于其精妙的架构设计。
首先,它采用了 MoE (混合专家) 架构。模型每层包含32个专家网络,但每个 Token 的前向传播仅激活其中4个(约13%的激活率)。这意味着,尽管其总参数量高达21B,但单次推理的计算量仅相当于一个 3.6B 的稠密模型,极大地降低了硬件门槛。同时,专家网络部分采用了 MXFP4 量化,将模型尺寸压缩至原来的四分之一。
为了应对长文本处理带来的计算挑战,gpt-oss 采用了交替注意力机制:一半的注意力层使用全上下文(Full Attention),另一半则使用仅关注前128个 Token 的滑动窗口注意力(Sliding Window Attention)。这种设计将一半注意力计算的复杂度从 O(n²) 优化到了 O(n×w),是其能够高效处理长序列的关键。
除了这些宏观设计,gpt-oss-20b 的 Attention 结构中还蕴含着一些非常有趣的设计。
1. Attention Sinks:滑动窗口的“稳定锚”
这是一个在其他模型中非常罕见的设计。我们知道,标准的注意力机制容易在序列开头形成“注意力汇点 (Attention Sinks)”,这些初始 Token 会像锚一样稳定全局注意力。然而,当使用滑动窗口时,这些头部的 Token 会被逐渐移出窗口,导致注意力分布变得不稳定。
gpt-oss 通过在序列末尾显式地添加一个可学习的 sinks 向量来解决这个问题。这个 sinks 作为一个固定的“锚点”,确保即使在窗口滑动时,注意力也有一个稳定的归宿,从而维持了模型的推理连贯性和效率。
2. “注意力心跳”:一项揭示架构特点的发现
gpt-oss-20b 依然保留了 Attention Bias,而许多新模型(如Qwen2系列)已转向 LayerNorm。通过分析我们发现,gpt-oss 的 Bias 设计得非常克制(仅 Q-Proj 有微小 Bias,K-Proj 全为0),避免了 Qwen2 系列中因 Bias 过大导致的 Q@K^T 溢出风险。
然而,当我们进一步探究其 Q@K^T 的原始 Logits 分布时,一个极其规律且引人注目的现象浮出水面。
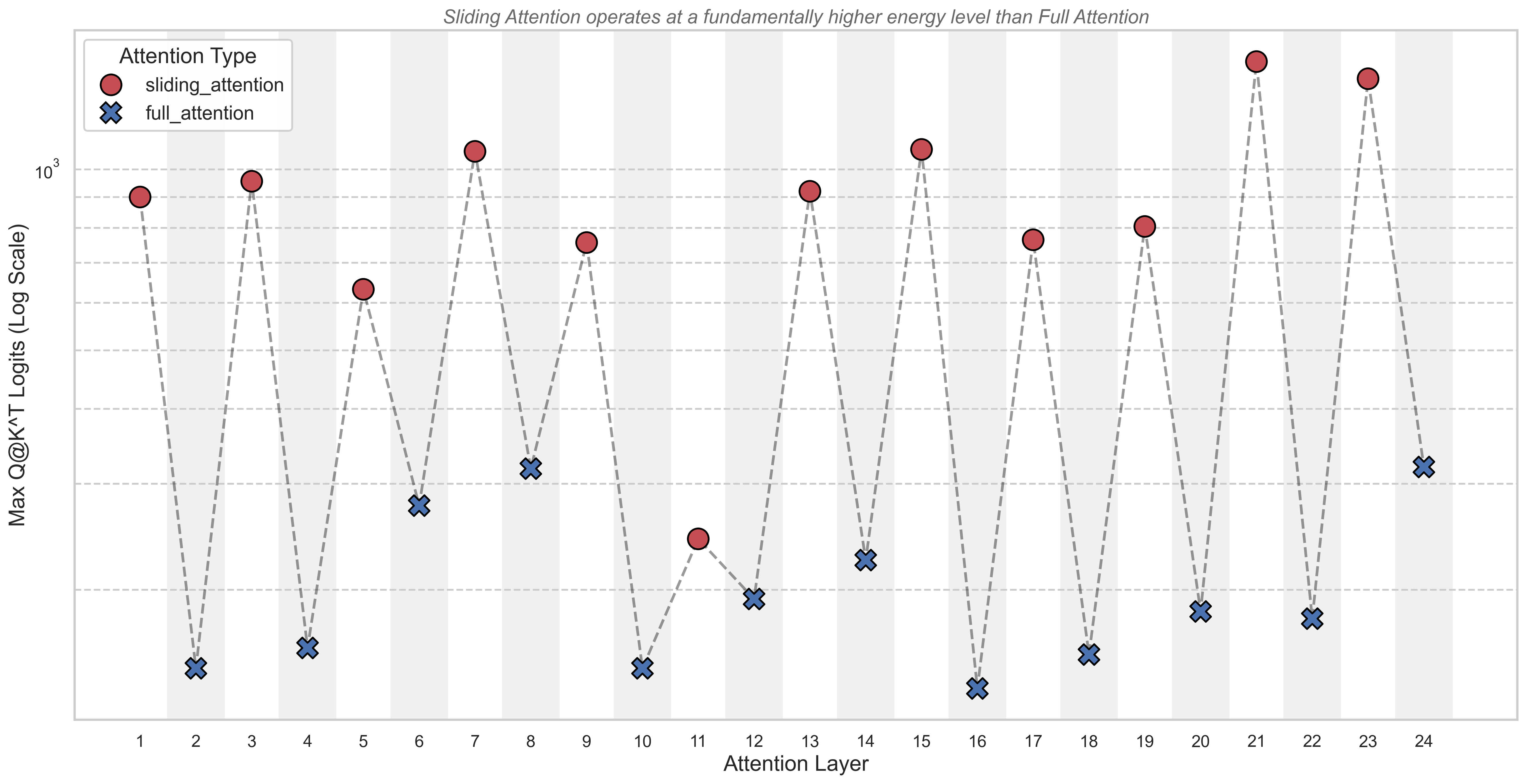
如图所示,模型的注意力表现出一种完美交替的“高峰-低谷”模式:
- 奇数层 (sliding_attention),构成了图中所有红色的“山峰”。这些层的
Q@K^TLogits 值异常之高,动辄达到数百甚至上千。 - 偶数层 (full_attention),则构成了图中所有蓝色的“谷底”。这些层的
Q@K^TLogits 值则要低得多,通常只有前者的十分之一甚至更少。
这个巨大的、数量级上的差异,并非随机伪影或由偏置项驱动,而是 gpt-oss-20b 在架构层面的一种深刻的功能特化 (Functional Specialization)。
原因解析:两种注意力层的“能量”分工
这个“注意力心跳”的根本原因在于,模型在训练中为两种注意力层学会了生成能量(即向量范数)完全不同的 Q 和 K 向量。
- Sliding Attention 层:“高增益”的局部信号放大器
- 定位:这些层是“局部专家”,视野狭窄。
- 任务:由于看不见全局,它们必须在有限信息中,对最关键的局部模式做出毫不含糊、决定性的判断。
- 实现:模型通过生成高范数(高能量)的 Q/K 向量来实现这一点。当两个高能量向量对齐时,它们的点积会变得非常巨大,就像一个高增益放大器,在进入Softmax前就几乎“内定”了胜者,确保最强的局部信号能被稳定传递。
- Full Attention 层:“低增益”的全局信息协调者
- 定位:这些层是“全局战略家”,视野广阔。
- 任务:它们的职责是审慎地评估和协调长距离依赖关系,这需要的是灵活性,而非武断。
- 实现:模型通过生成范数较小(低能量)的 Q/K 向量,使得在Softmax前,各个Token的竞争更温和公平。这让模型可以同时融合多个来自不同位置的弱信号,从而发现复杂的全局模式。
3. “短胖” vs “瘦长”的架构哲学
最后,模型间的宏观架构差异也值得玩味:
- gpt-oss-20b: 24层架构,相对“短胖”。
- Qwen系列: 通常为48层甚至更多,相对“瘦长”。
这种差异或许能解释它们的能力倾向:gpt-oss-20b“短胖”的结构让每层拥有更高的参数密度,可能更利于知识的存储和检索;而Qwen“瘦长”的结构通过更多层级的深度非线性变换,可能在逻辑推理和多步思考上更具优势。这也与我们在“智力测试”中观察到的“知识检索型”vs“情境推理型”的差异不谋而合。
MNN 适配与性能表现
为了将 gpt-oss-20b 的强大能力带到端侧,MNN 框架针对其独特架构进行了深度适配和优化。
- MoE 适配:为简化导出流程,MNN 将 gpt-oss 的原生 MoE 实现转换为与 Qwen2-MoE 兼容的格式。
- 注意力优化:初期通过
attention_mask实现滑动窗口,未来将持续优化以实现更高的计算效率。
实测性能
| 平台 | Prefill 速度 | Decode 速度 |
|---|---|---|
| OnePlus (骁龙8 Gen3) | 13.68 tokens/s | 11.35 tokens/s |
| Mac M3 Pro | 62.72 tokens/s | 23.98 tokens/s |

移动端运行截图显示了gpt-oss-20b在手机上的流畅表现
模型下载与快速部署
下载模型文件后,即可通过 MNN 的标准推理接口轻松调用,移动端可以使用 MNN Chat APP快速体验。
- ModelScope: gpt-oss-20b-MNN
- HuggingFace: gpt-oss-20b-MNN
- MNN Chat APP: apk
结语:当未来照进现实
完成对 gpt-oss-20b 的所有测试和分析后,我心中涌起一阵强烈的感慨。AI 的发展速度如此迅猛,以至于那个两年前初次让我感到震撼、认为遥不可及的 GPT,如今其同等级别的能力,已经安然运行在我的掌心之中。
从云端的庞然大物,到手机里的高效智能,这不仅是参数和代码的迁移,更是技术民主化的又一次伟大实践。这让我无比振奋,也让我对未来充满期待——端侧的 AI 能力必将日益强大,一个更加智能、更加个性化的世界正在我们眼前展开。
Enjoy Reading This Article?
Here are some more articles you might like to read next: