模型之战的下半场,烽火已经烧到了端侧。继阿里Qwen之后,腾讯混元也学着一次性发了覆盖多种大小的端侧模型。这种直接对标的打法,让这场“国产内战”变得非常有看点。
我一直比较关注端侧推理,这次正好把两个大厂的同级模型拉出来,硬碰硬地比一下。不扯别的,就看重合评测集里的硬核数据,看看指令微调之后,到底谁才是端侧场景的更优选。
性能对比
评测集就选这六个,都是硬骨头,覆盖了数学、科学、代码、指令遵循和工具调用这些核心能力:
- AIME’24 & AIME’25: 数学竞赛,纯看逻辑推理。
- GPQA-Diamond: 专业科学难题,看知识和推理。
- LiveCodeBench: 真实环境代码能力。
- IF-Eval: 能不能听懂人话,按复杂指令办事。
- BFCL v3: Agent能力,就是用工具干活的能力。
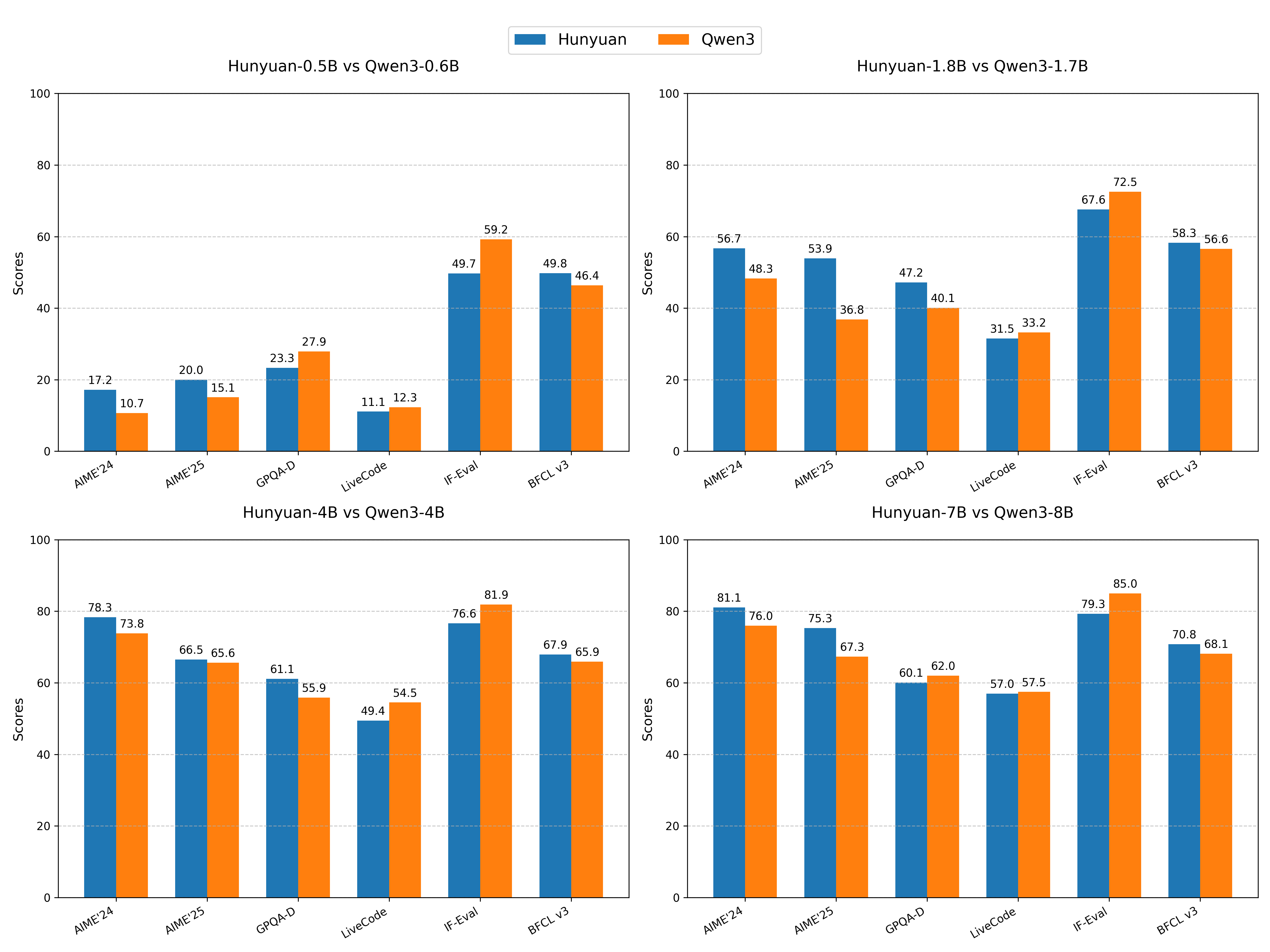
入门级 (0.5B vs 0.6B)
| 评测基准 | Hunyuan-0.5B-Instruct | Qwen3-0.6B |
|---|---|---|
| AIME’24 | 17.2 | 10.7 |
| AIME’25 | 20.0 | 15.1 |
| GPQA-Diamond | 23.3 | 27.9 |
| LiveCodeBench | 11.1 | 12.3 |
| IF-Eval | 49.7 | 59.2 |
| BFCL v3 | 49.8 | 46.4 |
主流级 (1.8B vs 1.7B)
| 评测基准 | Hunyuan-1.8B-Instruct | Qwen3-1.7B |
|---|---|---|
| AIME’24 | 56.7 | 48.3 |
| AIME’25 | 53.9 | 36.8 |
| GPQA-Diamond | 47.2 | 40.1 |
| LiveCodeBench | 31.5 | 33.2 |
| IF-Eval | 67.6 | 72.5 |
| BFCL v3 | 58.3 | 56.6 |
甜点级 (4B vs 4B)
| 评测基准 | Hunyuan-4B-Instruct | Qwen3-4B |
|---|---|---|
| AIME’24 | 78.3 | 73.8 |
| AIME’25 | 66.5 | 65.6 |
| GPQA-Diamond | 61.1 | 55.9 |
| LiveCodeBench | 49.4 | 54.5 |
| IF-Eval | 76.6 | 81.9 |
| BFCL v3 | 67.9 | 65.9 |
旗舰级 (7B vs 8B)
| 评测基准 | Hunyuan-7B-Instruct | Qwen3-8B |
|---|---|---|
| AIME’24 | 81.1 | 76.0 |
| AIME’25 | 75.3 | 67.3 |
| GPQA-Diamond | 60.1 | 62.0 |
| LiveCodeBench | 57.0 | 57.5 |
| IF-Eval | 79.3 | 85.0 |
| BFCL v3 | 70.8 | 68.1 |
数据分析
-
跑分下来,两边的画像非常清晰。 Hunyuan的进化路径非常明确,就是猛点 “推理” 和 “增强的代理能力” 这两个技能点。从0.5B到7B,它在AIME(数学)和BFCL(工具调用)上几乎一路领先。Qwen3则更像个“六边形战士”,在IF-Eval(指令遵循)和LiveCodeBench(代码)上表现稳定且强大,通用基础能力很扎实。
-
7B vs 8B的对决最有意思。 参数量更小的Hunyuan-7B,在最难的数学(AIME)上反超了更大的Qwen3-8B,这说明Hunyuan的参数效率在推理任务上非常高。但Qwen3-8B凭借更大的体量,在知识、代码和指令遵循上还是更强,综合实力依然是标杆。
Benchmark之外的亮点
除了跑分,Hunyuan这次还带了两个Qwen没有的“杀手锏”,而这可能才是决定某些应用场景选型的关键。
-
超长上下文:原生256K vs 32K 这可能是最“不讲道理”的优势。Hunyuan原生支持256K的上下文窗口,这直接是Qwen3原生32K的8倍。这意味着什么?处理超长文档、几十页的财报、把一整本书扔进去当知识库…这些场景Qwen3可能就很难搞,但Hunyuan能直接吃下,而且官方宣称在长文本任务上性能稳定。对于想做长文本分析、RAG增强等应用的开发者来说,这吸引力太大了。
-
为Agent而生的设计 上面的BFCL跑分已经证明了Hunyuan在工具调用上的领先。这不只是“碰巧”考得好,而是腾讯在设计模型时,就奔着让它当一个能干活的Agent去的,而不是一个纯粹的聊天机器人。这一点在τ-Bench和C3-Bench等其他Agent评测中也得到验证,说明它的这个优势是系统性的。
总结一下
所以到底怎么选?结论已经非常清晰了:
-
选Hunyuan,如果你需要一个“长文本分析专家” + “超级助理(Agent)” 如果你的应用场景需要处理上万甚至十万字以上的文档,或者需要模型作为核心,去调度各种外部API和工具来完成复杂任务,那Hunyuan是好的选择。它在这两个方向上优势太明显了。
-
选Qwen3,如果你想要一个“可靠的全能执行者” + “编程好帮手” 如果你的需求是构建一个能准确理解用户各种指令的通用聊天助手,或是在代码生成、调试等开发场景中寻求稳定可靠的帮助,那基础更全面、指令遵循能力更强的Qwen3依然是那个不会错的选择。
个人思考:混合推理,是条好走的路吗?
这里有个很有意思的细节。
Hunyuan这次也提了“快慢思考”混合推理,这和之前Qwen3的做法很像,想让一个模型满足不同场景下对速度和精度的要求。
但耐人寻味的是,Qwen3最新的版本反而把这条路给放弃了,直接把Thinking和Instruct拆成了两个独立模型。
所以,“一体两用”的混合推理,到底是不是一条好走的路?
Qwen3这波操作,看起来就像是踩过坑之后做的决定。这其实也印证了我自己做微调和部署时的感觉:这种混合模式听起来很美,但在实际部署、量化和持续优化上,远不如两个权责清晰的独立模型来得直接和高效。一个模型要同时兼顾两个差异巨大的优化目标,往往意味着两边都做不到极致。
Hunyuan现在还在坚持这条路,后续的效果和社区反馈会怎么样,值得我们持续观察。
压轴好戏:MNN支持
MNN第一时间给出了Hunyuan系列模型的支持,安装MNN Chat可以直接在手机上体验Hunyuan的模型。
